Phase 4 - SOFA Score Calculation
Python Code Details
Below are the codes involved in this phase for calculating SOFA Score.
> IDR_SOFA.py
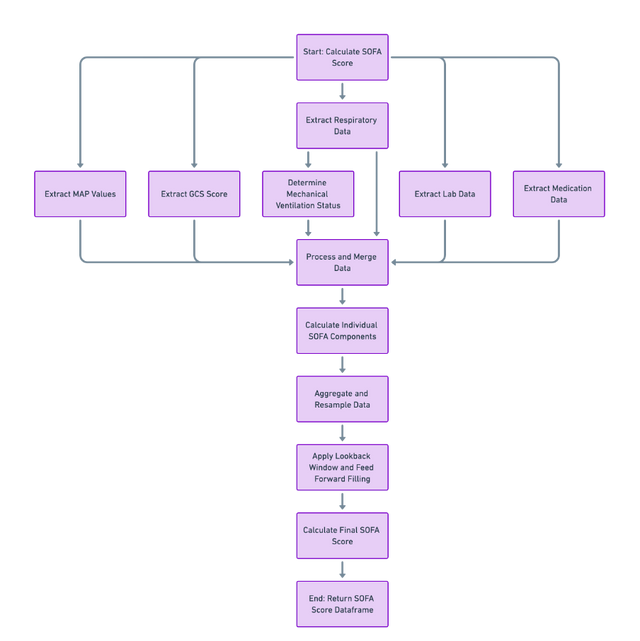
This script calculates the Sequential Organ Failure Assessment (SOFA) score, which is a metric used in the medical field to assess the extent of a patient's organ function or rate of failure.
WORKFLOW
Data Preparation and Extraction
The script imports necessary libraries and defines functions to process and extract relevant clinical data. This data includes blood pressure measurements, Glasgow Coma Scale (GCS) scores, respiratory data, laboratory results, and medication information.
Determine Mechanical Ventilation Status
Function ‘determine_mv’, is used to ascertain the mechanical ventilation status of patients. This involves analyzing respiratory data to identify patients who are under mechanical ventilation based on specific criteria.
Calculate SOFA Score
Function ‘calculate_sofa’, orchestrates the SOFA score calculation. It involves several steps:
- Extracting and processing various clinical parameters such as mean arterial pressure (MAP), GCS score, respiratory data (like FiO2 and SpO2), and laboratory results (bilirubin, platelets, creatinine, PaO2).
- Determining the use of vasopressors and the status of mechanical ventilation.
- Calculating individual components of the SOFA score, which assess different organ systems: cardiovascular, respiratory, hepatic, coagulation, neurological, and renal.
- Aggregating these components to compute the overall SOFA score for each patient.
- Data Aggregation and Resampling: The script aggregates the data over time, resampling it to align with specific time intervals. This step is crucial for tracking the progression of organ failure over time.
Output Generation
The final output is a DataFrame that contains the calculated SOFA scores for each patient, which can be used for clinical assessment and decision-making.
Flowchart of Idr_sofa.py
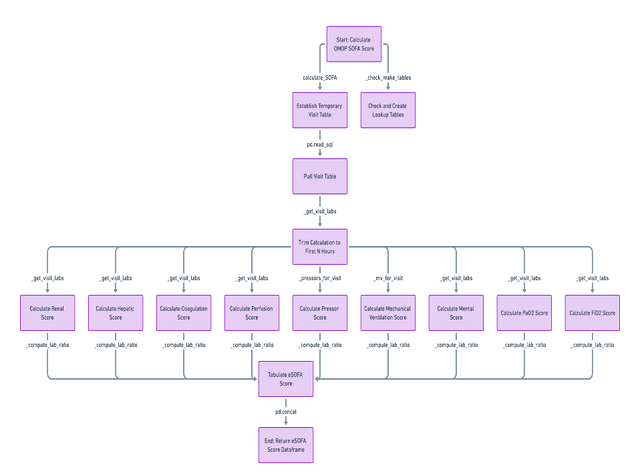
> OMOP_SOFA.py
This script calculates SOFA (Sequential Organ Failure Assessment) scores using data from an OMOP (Observational Medical Outcomes Partnership) database.
WORKFLOW
Database Connection and Data Retrieval
The script connects to an OMOP database using SQL queries. It retrieves relevant clinical data required for SOFA score calculation. This includes data from various tables like visit_occurrence, measurement, drug_exposure, and device_exposure.
Data Preparation and Processing
The script processes the retrieved data to prepare it for SOFA score calculation. This involves creating temporary tables, checking and creating lookup tables, and ensuring data consistency and correctness.
Calculation of Individual SOFA Components
The script calculates individual components of the SOFA score, which assess different organ systems. This includes:
- Renal score (based on creatinine levels or urine output)
- Hepatic score (based on bilirubin levels)
- Coagulation score (based on platelet count)
- Cardiovascular score (based on blood pressure and use of vasopressors)
- Respiratory score (based on PaO2/FiO2 ratio and mechanical ventilation status)
- Central Nervous System score (based on the Glasgow Coma Scale)
- Tabulation of eSOFA Score: The script includes the calculation of an extended version of the SOFA score, known as eSOFA, which might include additional parameters or modified criteria.
Aggregation and Resampling of Data
Similar to idr_sofa.py, this script aggregates and resamples the data over specific time intervals. This is important for monitoring the progression of organ failure over time.
Output Generation
The output is a DataFrame containing the calculated SOFA and eSOFA scores for each patient visit in the database. This data is crucial for clinical assessments and can be used for research or healthcare analytics.
Flowchart of omop_sofa.py