Phase 1 - Data Preprocessing
Python Code Details
Below are the codes involved in this phase for the data cleaning, coordination, and merging processes of the Electronic Health Data from IDR.
> Run_pipeline.py
This file contains the run_IDR_pipeline function, which is called from the main.py file.
WORKFLOW
Trigger run_IDR_pipeline function
> phase_I_through_III_coordinator.py
This script handles the structured process for executing a three-phase data operation, starting with initialization and conditional checks for pre-completion. This file contains functions related to the coordination of phases I, II, and III of the pipeline. It includes functions like run_phase_I, run_phase_II_and_III, and run_phases_I_II_III, which handle various tasks such as creating lookup tables, cleaning files, labeling files with merged IDs, and running these phases in parallel.
WORKFLOW
Initialization
- Import required modules and tools
- Load custom modules/functions necessary for coordinating phases I, II, and III.
- Decision: Check if merging has already been completed. If Completed then Skip to the end; Else, Proceed to "Retrieve Batches."
Retrieve Batches
- Get batches from the directory using get_batches_from_directory function.
- Execute run_phase_I function
Execute run_phase_I function
This function internally calls the function (or functions) associated with Phase I processing that likely involves data cleaning, processing, and saving operations. Any errors or conditions will be logged and handled appropriately.
Execute run_phase_II function
Execute run_phase_III function
Ensure Completion Status of all Phases
After the completion of execution of all the above functions, this decision check will ensure the completion status of all phases.
- If all Phases (I, II, III) are complete then it will write a success file indicating successful completion of all phases.
- If any phase is incomplete or encountered errors then it will log specific errors or issues related to the failed phase and exit without writing the success file.
> clean_data_phase1.py
This script automates the initial phase of data cleaning by loading, verifying, and formatting data sets, then executes a series of defined transformations and checks to ensure data integrity before saving the sanitized results for further processing.
WORKFLOW
Initialization
- Import required modules and tools specific to Phase 1
- Load custom modules/functions necessary
- Decision: Check if lookup table generation is done. If Completed then Skip this pre-processing phase(phase 1); Else, proceed with next cleanup steps in the phase.
Check IDR Data Transfer Completion Status
Decision: Check if IDR Data Transfer is complete. If Yes then
Calculate the number of batches.
Determine the optimal number of workers using calculate_optimal_workers.
Prepare arguments for parallel execution.
Else, Log Error and Exit
Execute Data Cleaning
- Retrieve Data
- Format Identifiers
- Merge Data
- Check Completeness
- Save Data
Parallel Execution of clean_data_phase_I function
Execute clean_data_phase_I function in parallel using the optimal number of workers.
Check completion status of individual batch processes
If All batch processes are complete:
- Write a success file for phase I
Else, Log an error and exit the program
> clean_internal_external_stations.py
This script handles fucntions to format, clean, and reconcile data from internal and external hospital stations, handling complexities such as patient transfers, overlapping data, and OR schedules integration, ultimately ensuring data integrity and usability for subsequent healthcare analytics.
WORKFLOW
Initialization
- Import required modules and tools
- Set global variables and Configure logging settings
- Formatting of datetime columns and renaming certain column prefixes is done
Load Data
- Load internal and external stations data with data integrity checks
- Organize data from the internal stations, handling patient transfer data within the hospital
Data Cleaning
- Resolve overlaps and inconsistencies in transfer data, correct duplications or errors
- Integrate OR case schedules with station data to track patient movements
Consistency Checks
- Check specific columns like STATIONTYPE for discrepancies
- Handle scenarios related to patient admissions, creating or modifying data rows as needed
Data Saving
- Impute missing data, particularly exit times from stations, using discharge information
- Use utility functions for data mapping, null assignments, and classifying station priorities
Finalize Clean Data
- Arrange the cleaned data for accessibility and comprehension
- Sort data by encounter IDs and entry times, moving certain columns for readability
- Save the cleaned data and write a success file to indicate completion
> clean_or_encounters_3.py
This script handles the functions to clean and validate Operating Room (OR) encounter data, employing specialized utility functions to ensure accurate surgery timelines, and preparing the data for seamless integration with broader healthcare datasets.
WORKFLOW
Initialization
- Import necessary modules and configurations
- Load any required custom functions for OR encounter data
Data Extraction
- Load data for OR encounters
- Validate the structure and content of the data
- Utilize utility functions for timestamp and percentage comparisons
Data Cleaning
- Standardize, format, and sanitize the data using functions such as _fill_proposed_start_stop_times to determine accurate surgery start and end times
- Convert times from integer to proper datetime formats with _convert_integer_time_to_datetime for precise time calculations
Data Validation
- Ensure data meets specific criteria, utilizing comparison functions to assess the start and end times of surgeries
- Cross-verify data with existing reference tables or sources, ensuring consistency and accuracy
Data Merging/Integration
Data Saving
Completion Checks
- Validate if all cleaning and processing steps were successful.
- If Yes then write a success file, else Log errors and specify the nature of any discrepancies.
> merge_encounters.py
This script streamlines healthcare data management by merging overlapping patient encounters into a cohesive record and updating encounter IDs, ensuring dataset consistency and integrity for subsequent analysis. It employs a series of functions for loading, cleaning, prioritizing, and labeling encounter data effectively.
WORKFLOW
Initialization
- Load dataframes or paths from files including billing accounts and admit discharge stations
- Configure logging settings, format datetime columns, and perform initial data cleaning
Check and Load DataFrames
- Load the primary encounter dataframe and lookup dataframe
- Apply initial filters to exclude non-inpatient admissions, and handle OR cases as specified
Data Processing
- Rename columns for consistency
- Use connectivity graph logic from merge_encounters to identify and merge overlapping encounters into a single consistent record
- Assign priorities with functions like _highest_priority_patient_type and _highest_priority_encounter_type to ensure the most relevant information is preserved
Updating IDs and Creating Lookup Table
- Generate new encounter IDs with update_encounter_ids for uniquely identifying merged encounters
- Create a lookup table mapping old encounter IDs to the new merged ones with create_encounter_lookup_table, a crucial step for data consistency
Data Labeling and Saving
- Label datasets with the new merged encounter IDs using label_df_with_merged_encounter_id, adaptable to various data structures and file types
- Save the processed data, now labeled and formatted correctly
Completion Checks
- Validate if all merging, labeling, and processing steps were successful.
- If successful, write a success file; otherwise, log errors and exit
Phase 1 Comprehensive Flowchart
Below is the comprehensive high level flowchart of entire Phase 1 processes
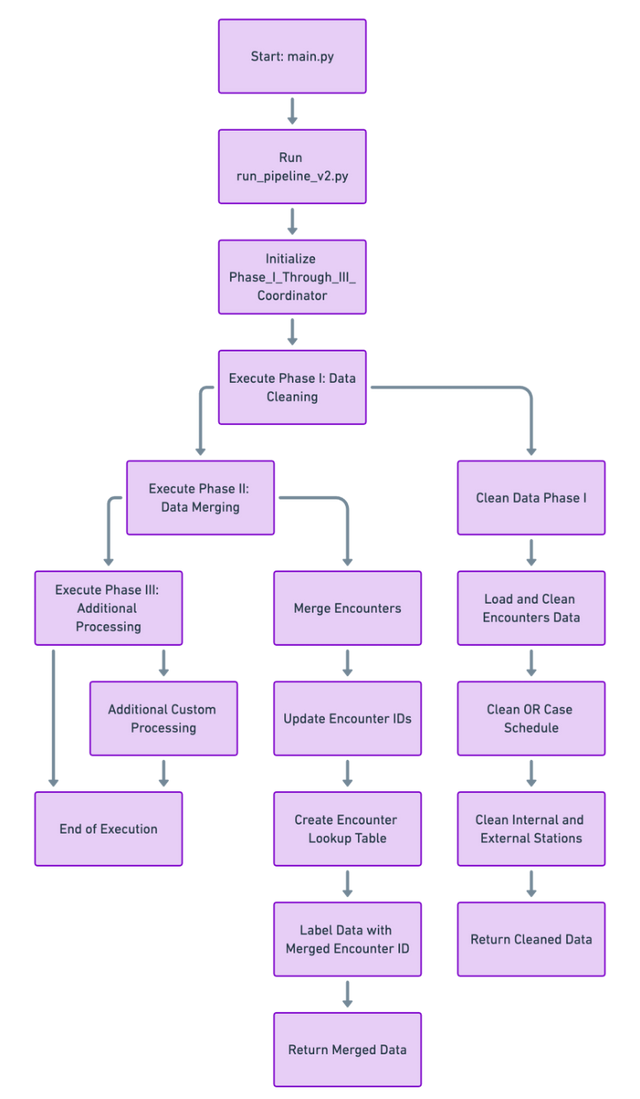
To get more details about low-level flow of Phase 1, access the flowchart at Detailed flowchart-Phase-I
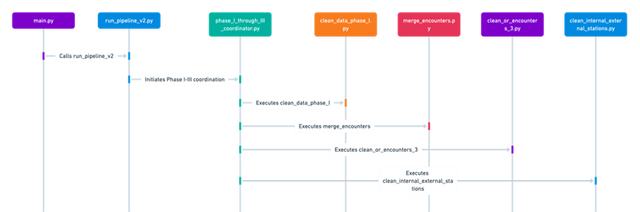
Below is the sequence flowchart to show the hierarchy of flow between files of Phase 1