Phase 2 - Data Cleaning
Python Code Details
Below are the codes involved in this phase for cleaning various types of healthcare data files.
> clean_files.py
This script does data cleaning within healthcare data preprocessing pipeline, targeting various dataset types for enhancement by applying cleaning strategies, leverages specific functions for different data types, and handles large files efficiently, all while ensuring the data's readiness for further analysis.
WORKFLOW
Initialization
- Import Modules and Functions for data cleaning
- Trigger 'clean_df' Function which performs the entire cleaning process for different types of healthcare data
Filename Components Extraction
- Extract Output File Path Components like file name and batch numbers
- It then Identifies the appropriate time index for visit detail labeling based on the file name, guiding the temporal aspects of the cleaning
Load and Clean Data Based on File Type
- Executes specific cleaning logic for each data type including but not limited to Blood Pressure, Respiratory, Labs, and Medications. This step involves calling dedicated cleaning functions for each data type, such as
clean_bp,clean_respiratory,clean_labs, andclean_meds.- If Blood Pressure Data, then it Calls
clean_bpfunction to clean blood pressure data. - If Respiratory Data, then it Calls
clean_respiratoryfunction for respiratory data. - If Labs Data, it calls
clean_labsfor laboratory results. - If Medication Data, it calls
clean_medsfor medication data. - If other Data Types, it applies corresponding cleaning functions like
clean_mac,clean_vitals,clean_diagnoses,clean_dialysis,clean_mobility, and others based on the file name.
- If Blood Pressure Data, then it Calls
- For files that require handling large datasets or have unique processing needs (e.g., medications), the script uses specific functions to manage these efficiently and avoid memory issues.
Data Saving and Final Cleanup
- The cleaned data is saved to the specified output paths, with the option to split into batches for larger datasets.
- To conserve disk space and maintain organization, intermediate files used during the cleaning process are removed after completion.
> append_station_info.py
This script has 'append_station_label' function that handles the missing data of DataFrame by appending station information, including station names and types, based on encounter IDs and time indexes.
WORKFLOW
Initialization
- Checks if internal_stations_df and df are pandas DataFrames.
- Initializes an in-memory SQLite database and transforms internal_stations_df and df into SQL tables within the SQLite environment.
Data Joining
- Performs an SQL query to join the target DataFrame with station data based on the encounter ID and a time index within the station's entry and exit times to enrich df with station and station_type.
Handling Missing Data
- Check if there are any missing station_type values in the resulting DataFrame.
- Further checks if encounter_df is provided.
- Utilizes encounter data to impute missing station_type values. This includes creating a temporary DataFrame for mapping missing types and merging it with the main DataFrame.
- Uses a default location value (default_location) for any station_type values that remain missing after attempting the data-driven imputation.
Updated Dataframe
- Removes temporary columns that were used for the imputation process.
- Returns the DataFrame with appended and imputed station information.
> clean_diagnoses.py
This script has 'clean_diagnoses' function that cleans and consolidates diagnosis data within healthcare datasets, enhancing its integrity and utility by standardizing dates, correcting encounter IDs, and enriching diagnoses details.
WORKFLOW
Datetime Cleanup and Standardization
- Formats date and time columns for consistency, a crucial step for accurate data comparisons and temporal joins.
- Combines encounter IDs spread across multiple rows into single rows to address data fragmentation.
Correction of Encounter IDs in Diagnoses
- If incorrect encounter IDs are found in the diagnosis file:
- Removes these IDs and fills in correct ones using the encounter file as a reference.
Labeling of Discharge Diagnoses
- If diagnoses are found in the encounters file for a specific encounter:
- Labels these diagnoses as present on admission (POA), distinguishing between pre-existing conditions and those developed during hospitalization.
- Adds admit diagnoses not previously recorded in the diagnosis file to provide a fuller picture of patient admissions.
Extraction and Processing of ICD Codes
- Extracts ICD-9 and ICD-10 codes, along with free-text diagnoses, formatting them to fit the diagnosis dataset structure.
- If diagnosis flags for POA are present:
- Assigns POA indicators.
- Prioritizes diagnoses based on primary or secondary status.
- If diagnosis flags for POA are present:
Merging and Final Cleanup
- Merges the processed diagnosis information back into the main dataset, correcting errors and filling in gaps.
- If any diagnosis data rows still lack POA indicators after processing:
- Assigns default POA status based on available data.
- If problem list status information is missing:
- Adds default values to ensure dataset completeness.
- If any diagnosis data rows still lack POA indicators after processing:
> clean_MAC.py
This script has 'clean_mac' function that processes and adjusts MAC values within healthcare datasets, engaging several functions to refine the data based on patient age and the specific anesthetic used.
WORKFLOW
Initialization
- Imports and constants are defined for use across the script.
- Initializes the cleaning process, orchestrating the flow and invoking other functions as needed.
- Converts encounter and birth dates to datetime format for calculation purposes.
Calculate Patient Age
- Invokes 'calculate_age' function to determine the patient's age at the time of the encounter.
- Maps patient ages to their respective encounters for later reference.
Prepare MAC DataFrame
- Renames and selects relevant columns for processing.
- Formats datetime and numeric fields for consistency.
Calculate MAC for Age=40
- Filters MAC dataframe for relevant anesthetic types.
- Invokes 'calculate_mac40' function for each row to compute the MAC value at age 40 based on the type of anesthetic used.
Adjust MAC Values Based on Actual Age
- Applies 'compute_mac_val' function to adjust the MAC values based on the actual age of the patient, using the age dictionary created earlier.
- It then tailors MAC calculations to the individual patient, factoring in the physiological changes that affect anesthetic concentration requirements.
- It then calls 'remove_artifacts' function to clean up unrealistic MAC values (outside the range of 0 to 2), ensuring data integrity.
- Merges the adjusted MAC values back into the main dataframe, organizing and preparing the dataset for analysis.
> clean_dialysis.py
This script has 'clean_dialysis' function that consolidates dialysis and CRRT (Continuous Renal Replacement Therapy) data into a single, clean DataFrame by standardizing column names and consolidating records.
WORKFLOW
Data Transformation
In dialysis_df,
- If the column 'measurement_name' exists:
- Rename 'measurement_name' to 'vital_sign_measure_name' and 'measurement_value' to 'meas_value'.
- Else:
- Identify columns common to both dataframes (ID columns and 'observation_datetime').
- Melt 'dialysis_df' to reshape data, with ID columns and 'observation_datetime' as 'id_vars', and the rest as 'value_vars'.
- Rename the melted variable column to 'vital_sign_measure_name' and the value column to 'meas_value'.
- Drop rows where 'meas_value' is NaN.
- Rename columns in 'crrt_df' for consistency:
- 'recorded_time' to 'observation_datetime'.
- 'group_display_name' to 'vital_sign_group_name' (if exists).
- 'group_measure_name' to 'vital_sign_measure_name' (if exists).
- 'measure_value' to 'meas_value'.
- Concatenate 'crrt_df' and 'dialysis_df' along rows.
- Drop rows with NaN in 'meas_value'.
- Return the unified and cleaned DataFrame.
> clean_mobility.py
This script has 'clean_mobility' function that handles mobility data cleaning process by transforming the dataset into a long format and removing any missing values.
WORKFLOW
Data Transformation
In mobility_df,
- Transform the mobility_df from wide to long format.
- id_vars: Specifies columns to remain vertical (unchanged), identified by intersecting mobility_df columns with key identifiers (pid, o_eid, eid, recorded_time, and batch_visit_detail_id).
- var_name: Sets the name of the new variable column to 'measure_name', which holds original column names.
- value_name: Sets the name of the new value column to 'meas_value', which holds the values of the original columns.
- Removes rows where the meas_value is NaN, ensuring the cleaned DataFrame contains only valid measurements.
- Returns the cleaned mobility_df in a long format with measurements standardized under measure_name and meas_value.
> clean_vitals.py
This script has 'clean_vitals' function that cleans vital signs data, specifically heart rate and temperature, including outlier removal and adjustment based on measurement source.
WORKFLOW
Initialization
- Imports necessary libraries and functions.
- Defines minimum and maximum acceptable values for heart rate and temperature.
- Checks if 'measurement_name' exists in 'vitals_df'. If so, reshapes the DataFrame using 'stack_df'.
Data Cleaning
- Converts Fahrenheit to Celsius if 'temp_celsius' is missing but 'temp_fahrenheit' is available.
- Filters columns, drops rows missing time or measured value, sorts by 'eid' and 'time_index', performs value adjustments based on source, and removes values outside acceptable range.
- Adjusts temperature based on source (_correct_temp_type function called within 'vitals_outlier_detection' for temperature sources).
- Performs similar filteration steps for heart rate data
- Returns two cleaned DataFrames: one for temperature and one for heart rate, ready for further analysis.
> label_visit_id.py
This script has 'label_visit_id' function that outputs a DataFrame with visit detail labels by matching entries to station data based on time and patient ID, optionally including station labels.
WORKFLOW
Visit Details Label Matching
- Prepares df and stations_df for SQL operations.
- Creates an in-memory SQLite database and loads both DataFrames.
- Executes an SQL query to join the DataFrames based on pid and df_time_index within the stations_df's entry and exit times.
- Optionally includes station label and type in the output based on include_station_label.
- Returns df with visit details labeled, including an intraoperative flag.
Phase 2 Comprehensive Flowchart
Below is the comprehensive high level flowchart of entire Phase 2 processes
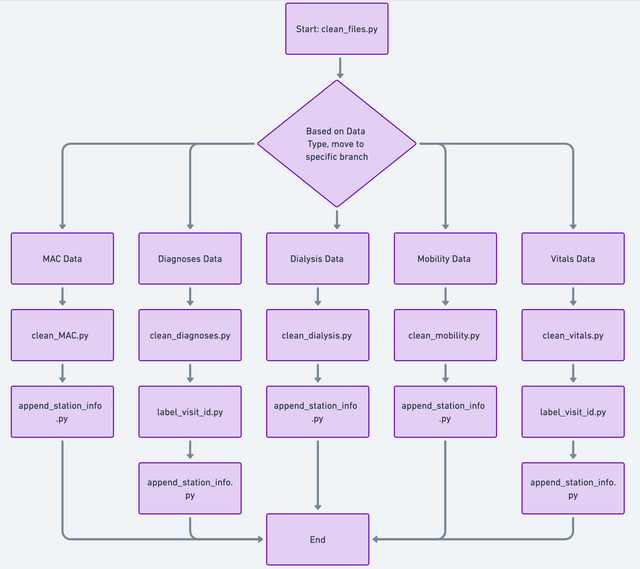
Start
Data Type Decision
Data Cleanup based on data type
- For MAC Data: Calls clean_MAC.py, which internally uses functions to calculate age-adjusted MAC values and to clean the data.
- For Diagnoses Data: Calls clean_diagnoses.py for standardizing diagnosis records. This process might involve using label_visit_id.py to label data with visit IDs based on station info.
- For Dialysis Data: Calls clean_dialysis.py to unify and clean dialysis and CRRT files.
- For Mobility Data: Directs to clean_mobility.py for melting and cleaning mobility measurements.
- For Vitals Data: Might call clean_vitals.py and label_visit_id.py for cleaning vital signs data and labeling them with visit IDs, respectively.
- Append Station Info: Utilizes append_station_info.py to enrich datasets with station-related information, possibly requiring visit IDs from label_visit_id.py.
Each script returns a cleaned or enhanced version of the dataset, ready for further analysis or integration into larger datasets.